How to avoid 5 testing pitfalls & run trustworthy experiments
Twitter: @robkingston, https://mintmetrics.io/
Broadly two avenues to increase results from experimentation
- Increase Velocity
- Run more tests, faster
- Increase Quality
- Run better tests, ideas
- Trustworthy results
Trustworthy experimentation is overlooked
...but it shouldn't be.
- Outcomes can be worth $Ks/$Ms in revenue
- Dodgy results enshrine false narratives
- Undermines credibility in all your work
Let's explore common pitfalls so you can identify & fix them.
Pitfall #1
Finance client testing new CTA design. Mild styling/markup change, passed extensive QA:
<button class="oldBtn">Create an account</button>
<a class="newBtn" href="/signup.html">Signup now</a>
After launching, the SaaS split testing tool reported
checkouts down -70%! 😧 %$#&!
Right, time for us to check what GA was reporting:
- Overall conversion is fine
- NO drop in checkouts
So, we go back to the SaaS tool:
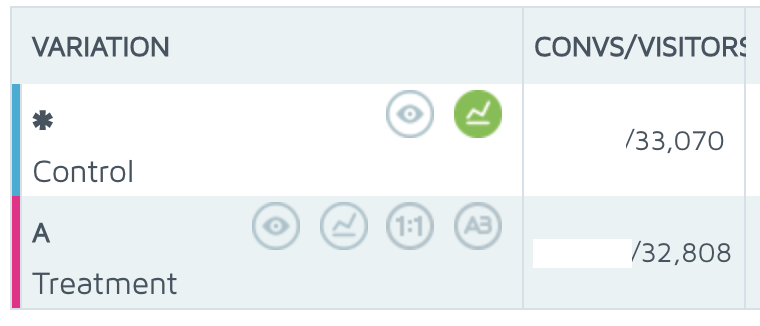
And then compared GA's figures:
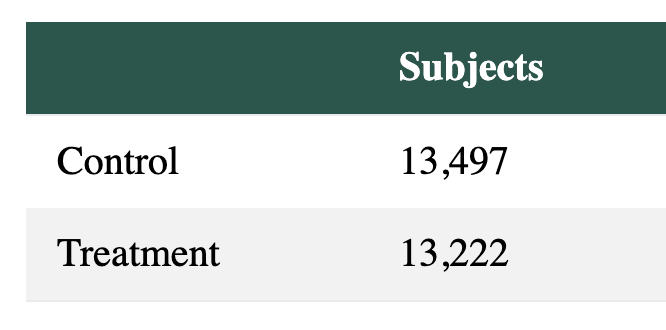
NB. Subjects = Visitors
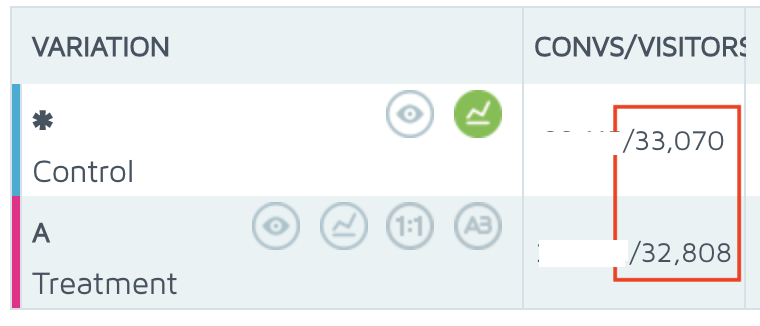
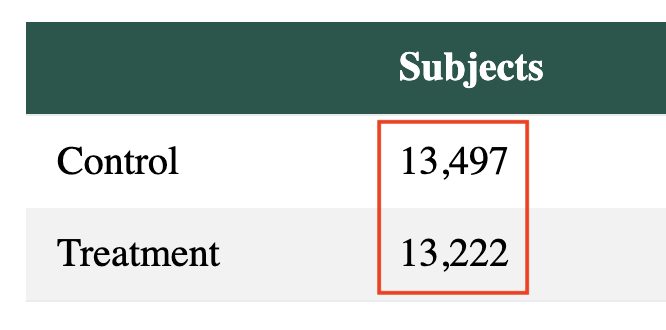
The SaaS tool tracked +150% more users bots.
"Checkouts" dropped -70% because bots didn't recognise the new CTA.
Moral #1: Beware of bad tracking / instrumentation
- SaaS testing tools' trackers often fail like this
- Always track tests into purpose-built analytics tools
- How to Integrate Optly/VWO/etc with GA
Pitfall #2
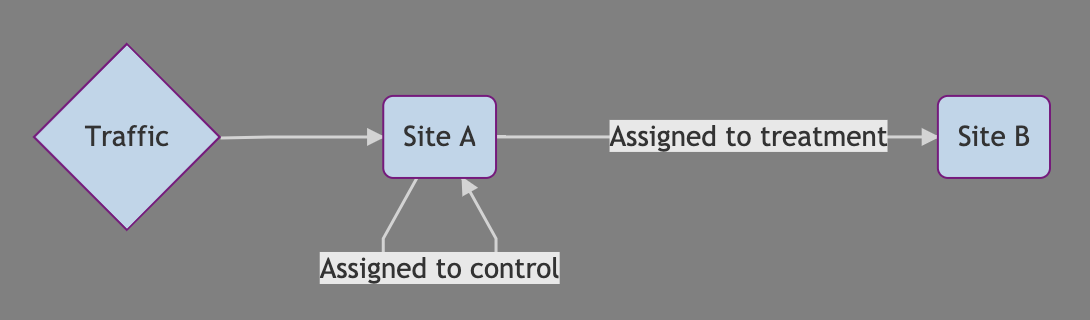
Ecommerce client testing major redesign. Used JS redirects for a 50-50 split test that needed back-end changes.
Load times will hurt the treatment, right?
Nope! Conversion rates were dead even...

But, traffic should be split 50-50.
Why does the control group have more?

- The redirect thinned out slower browsers
- The redirect executed before the tracking ran
Assuming even assignment it could be affected as much as -18%! A far cry from +1.2%...

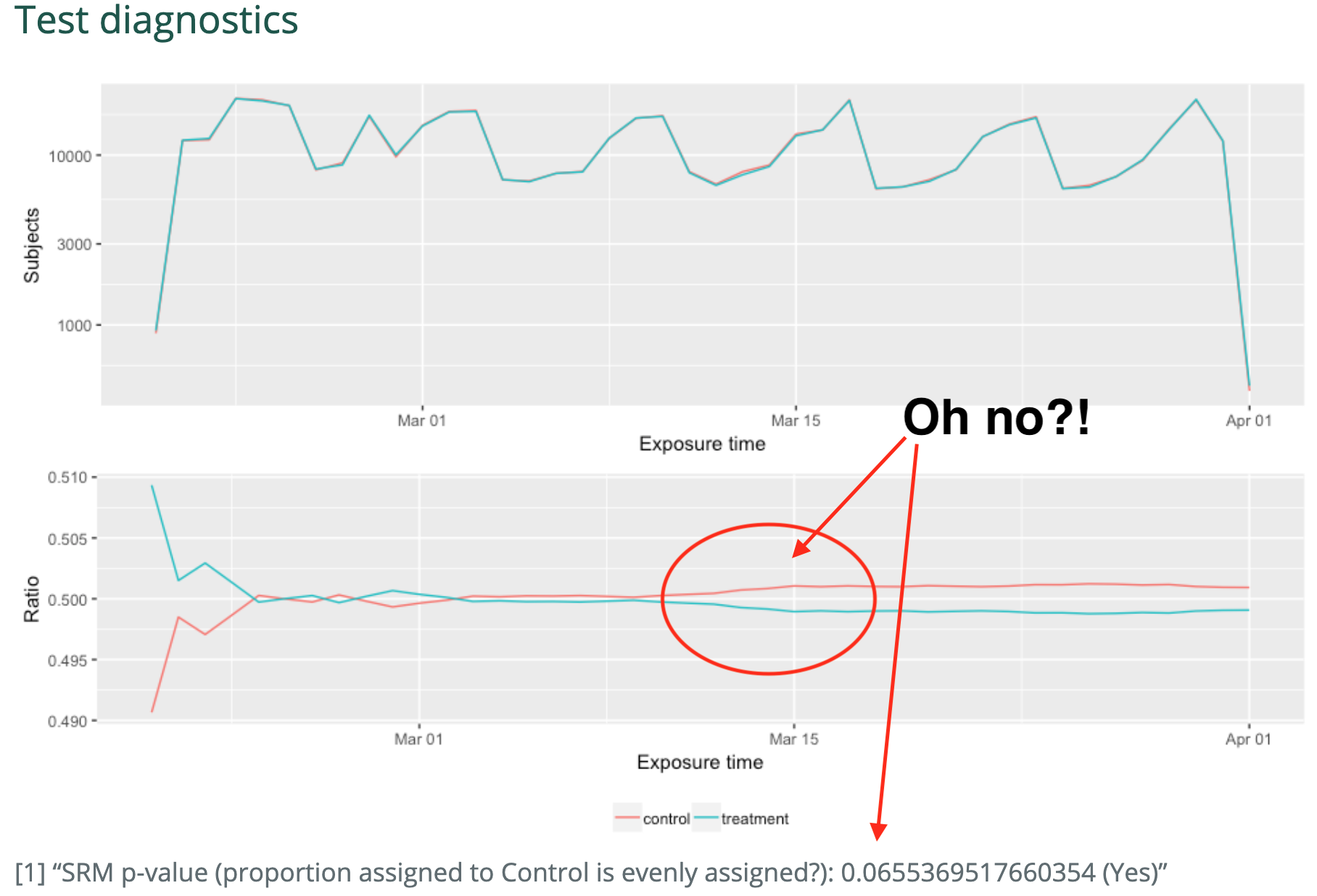
Moral #2: Avoid selection bias by watching your assignment ratio
Use "SRM" tests & plot your assignment over time
Pitfall #3
Another ecommerce client testing a major SERP listing redesign:
- Complex test with '000s lines of CSS/JS
- Passed several rounds of code review
- Lots of eyeballs on the test
Treatment was delivering a solid lift (Everything stat sig). Just 1-week out from completion...
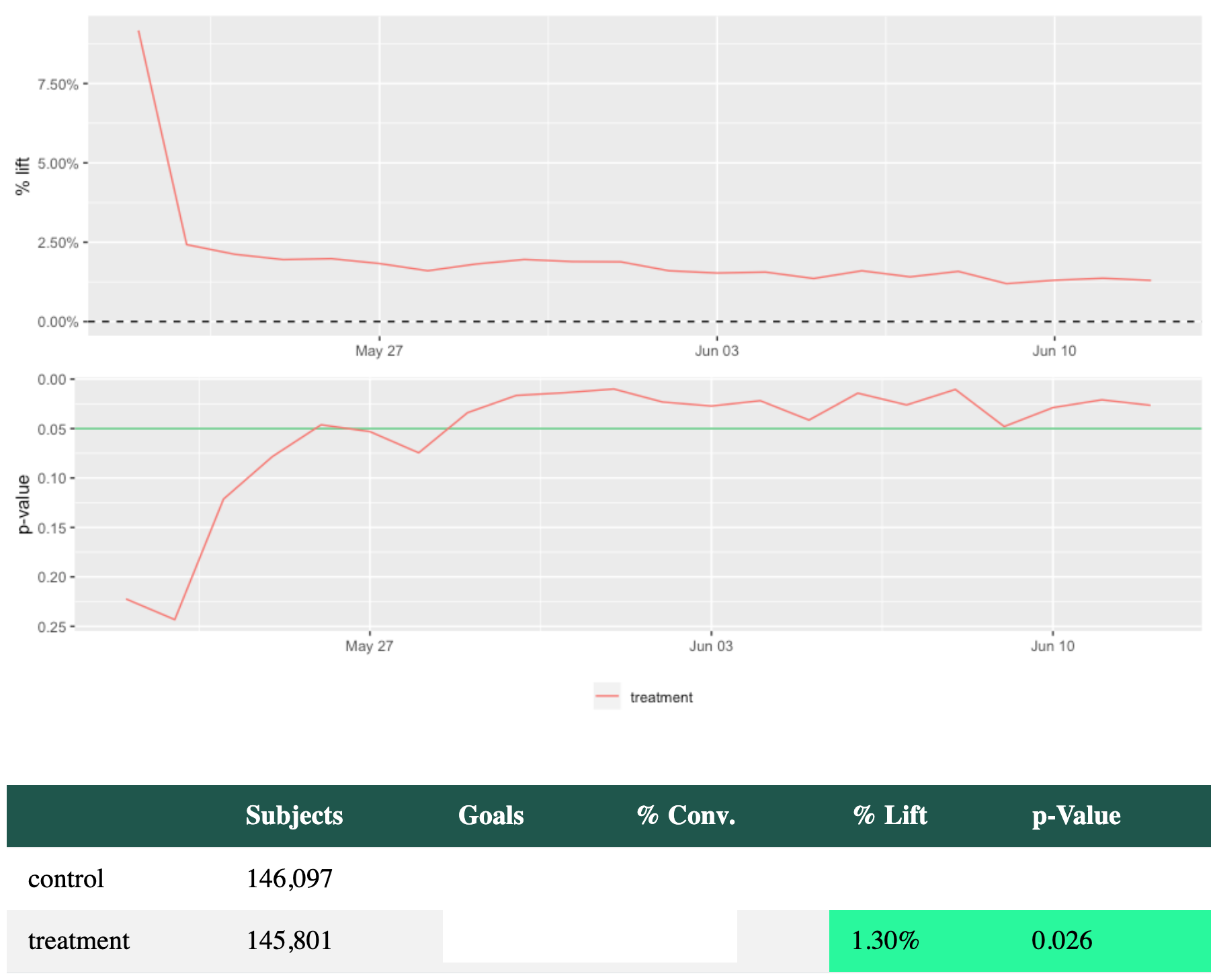
Days later, we check the results...
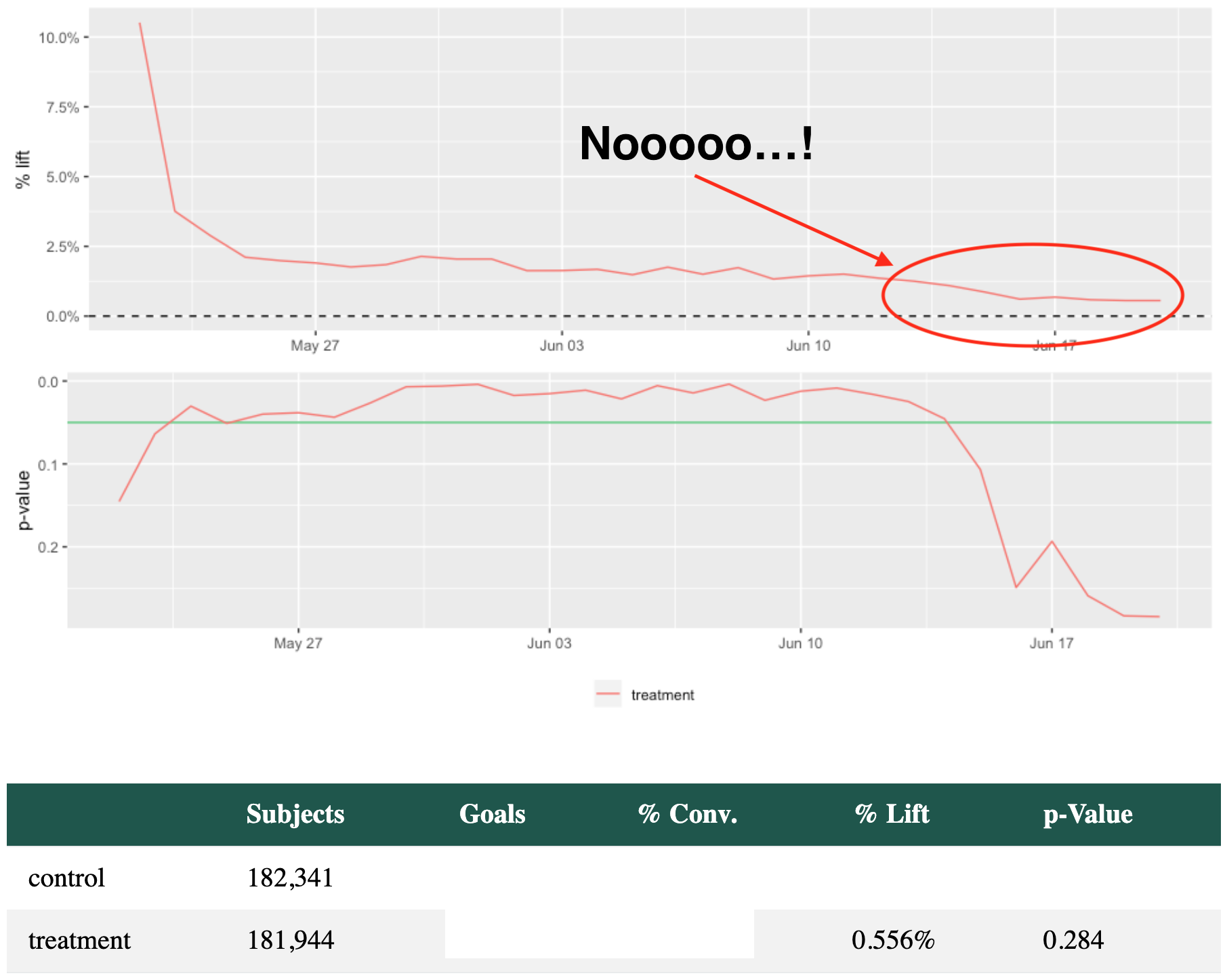
Time to investigate...
Errors spiked from the treatment group when a feature deployment broke our test pages.
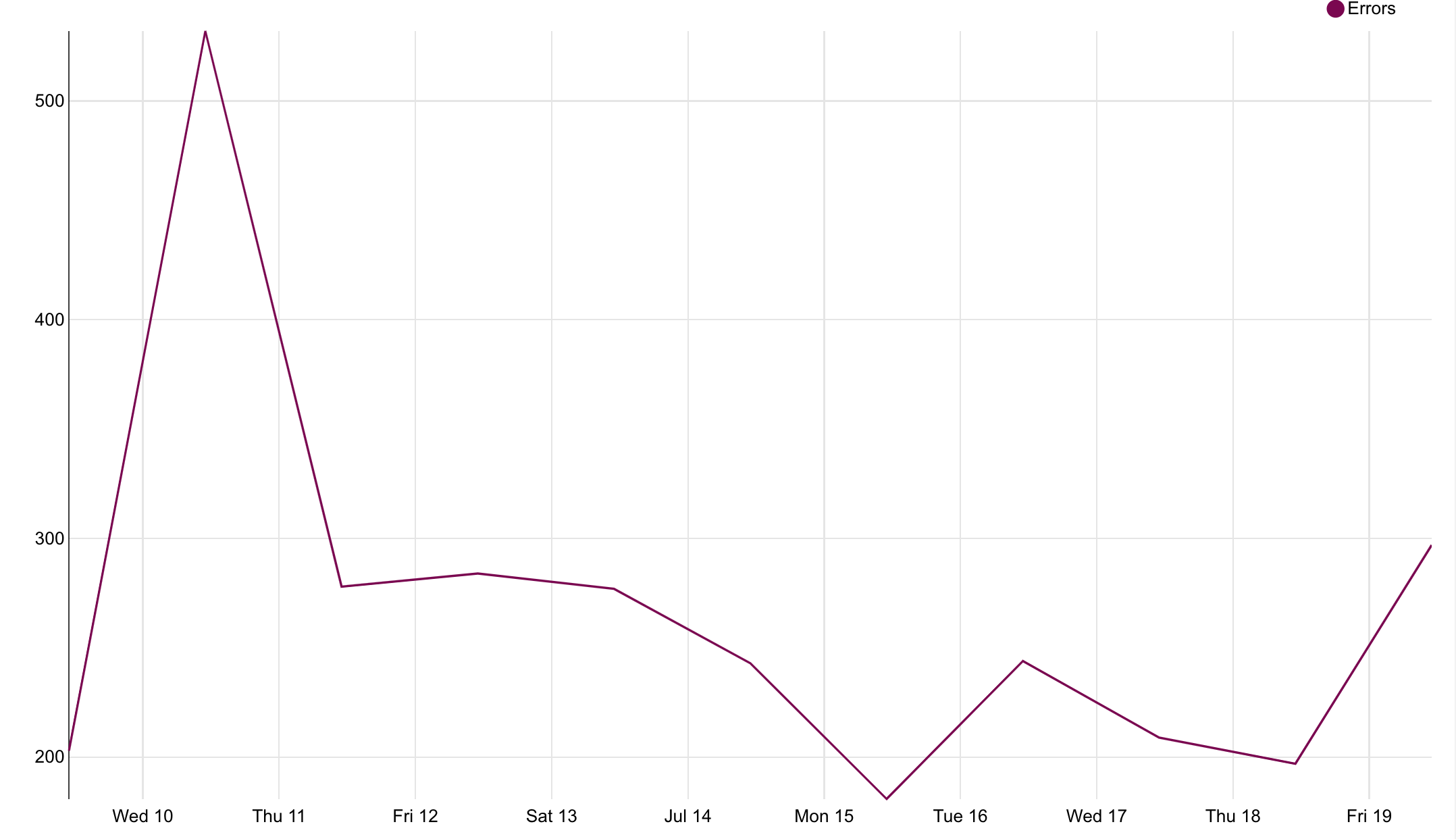
The whole page was unusable, risking $ooK's/revenue.
Fortunately, we had protection.
Erroring users were booted from the test so they could continue browsing unhindered.
Moral #3: Protect your users & app with error tracking & handling
- Tests bring new code, complexity (& even bugs)
- Give your ops teams peace of mind
- Start tracking & handling errors in variants
Pitfall #4
On a lead-gen site, someone wanted to run a really, really important test to lift engagement.
"It's such a good idea - it's full of personalisation and has a
fantastic PIE score!"
So, we built it, QA'd it, tested it and launch the experiment...
With the experiment live, we waited for a result...
2 months passed & no cigar!
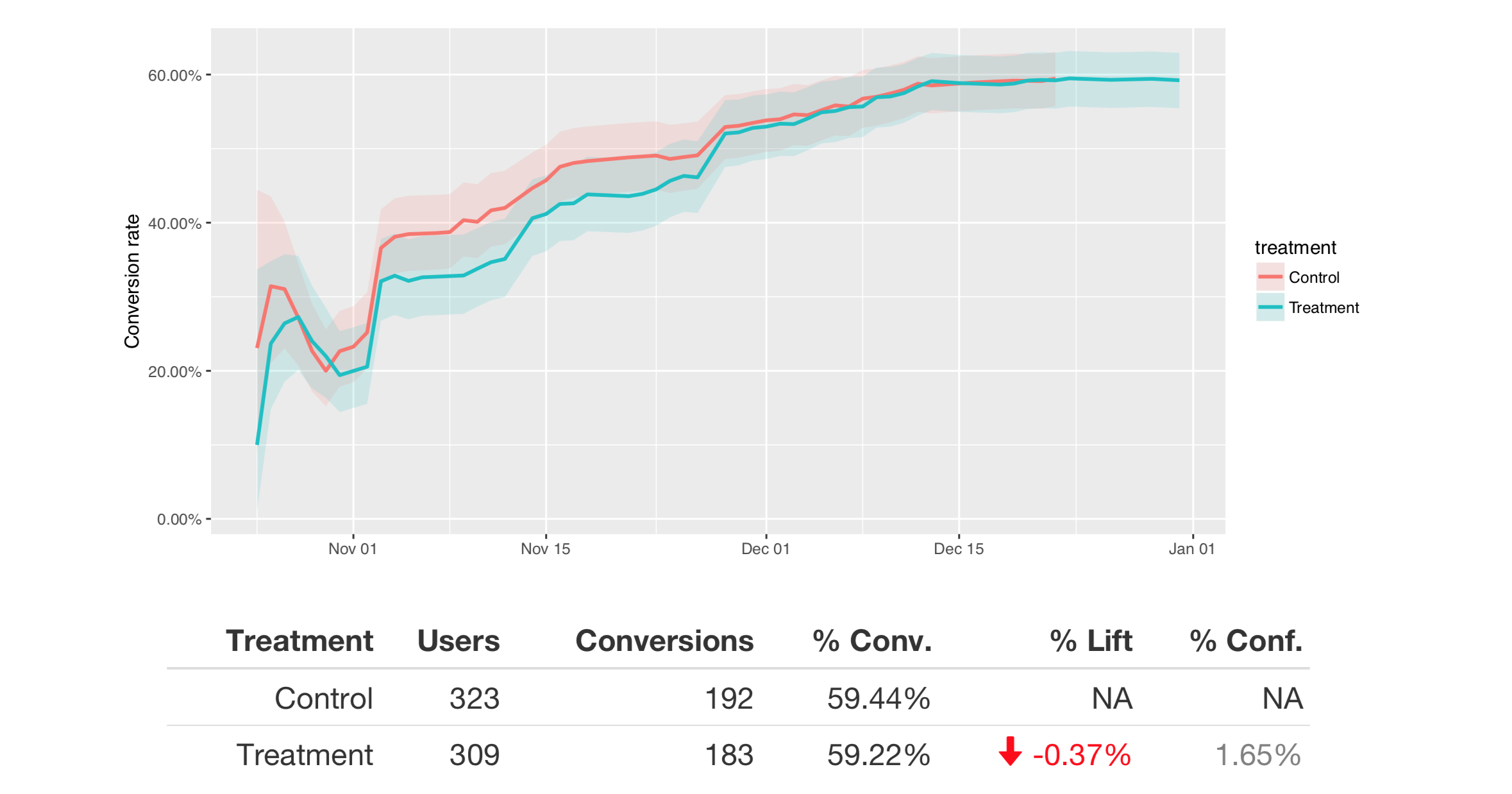
Moral #4: Always size experiments to see if it'll produce an outcome
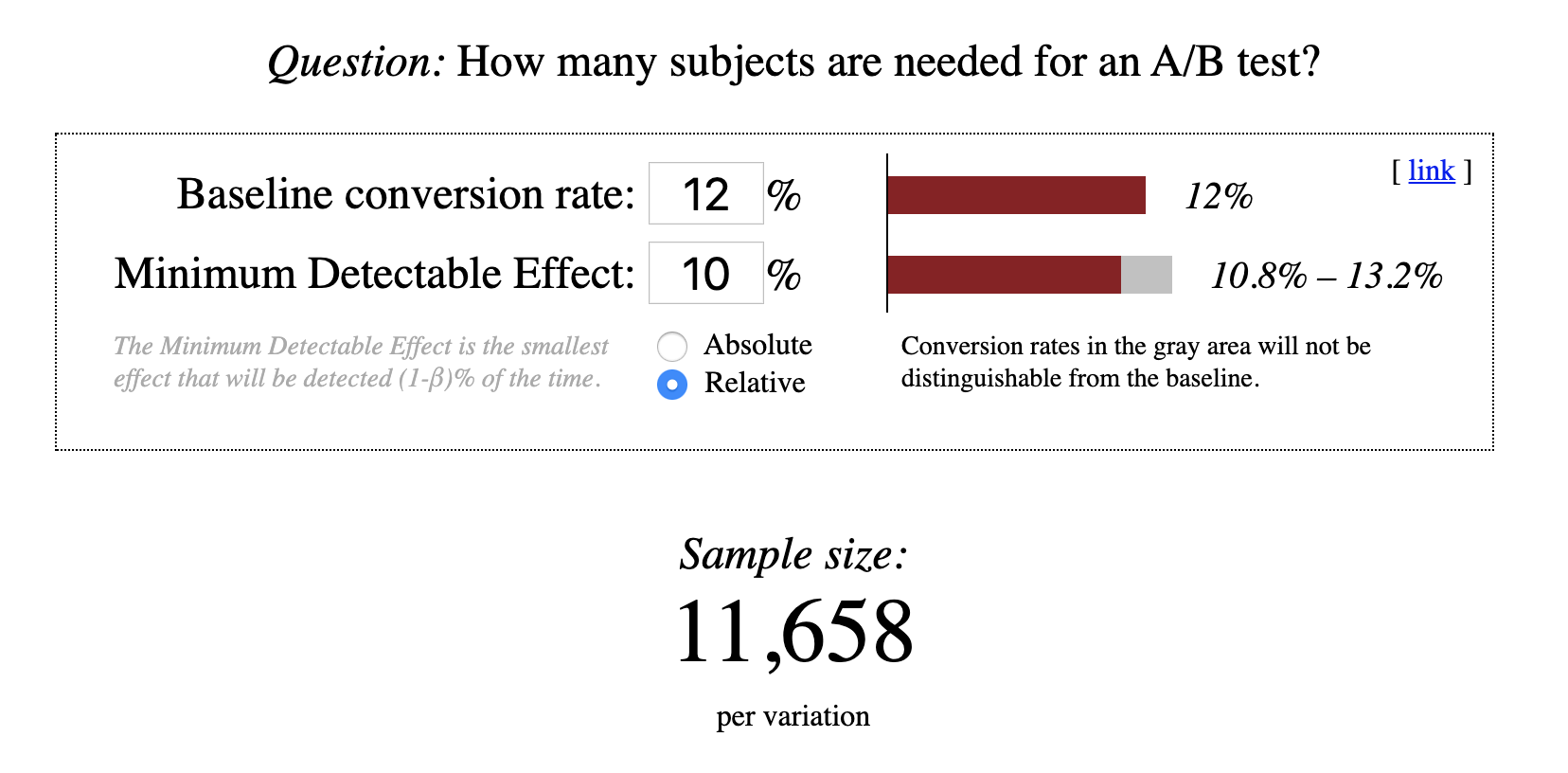
- Find your "Minimum Detectable Effect"
- Minimise effect of peeking on "stat sig results"
- Simple online calculators & Snowplow / R calculator
Pitfall #5
Hypothetical: Timmy wants to run a test on an ecommerce payments page (responsible for 100% of revenue).
"Let's redesign this step to make it fit our new brand..."
So, you build, test and QA it thoroughly.
On launch day, you publish it to 100% of traffic...
at 5pm on "Friyay". Job done ¯\_(ツ)_/¯
Yeah, nah.
Imagine a production config flag breaks the test.
Now, half the revenue is at risk.

Moral #5: Protect mission-critical apps with gradual ramp-up
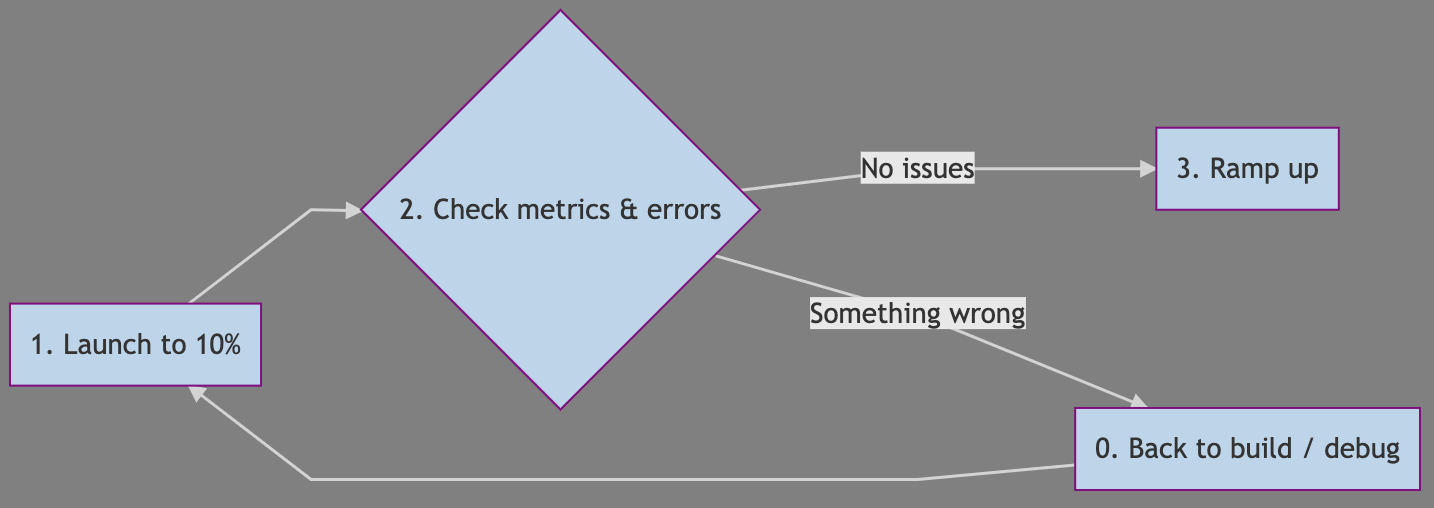
PS. It's easier to launch a contentious idea to 10% traffic, too!
Of course, there are many more pitfalls...
Hopefully now you know how easy they are to spot and solve!
Thanks for your time!
Any questions?
-
See the slides & links:
https://mintmetrics.io/wawmelbourne/ - Check out Mojito, our open-source split testing tool that eschews these values