Why you need error tracking & handling in your split tests


Remember the good old days of JS errors? (Image credit)
Building large, complex experiments introduces new logic, new code and sometimes new bugs. But most A/B testing tools don't perform error tracking or handling for you. So when you launch your experiment and it tanks...
...did your awesome new idea just not work? Or did bugs torpedo your idea?
Track bugs in your variant code and triggers
JS errors can be caused by lots of things and not all of them are caused by your variant code explicitly. They'll creep in from:
- Changes to the underlying code while the test is live
- Edge cases that were missed during QA
- Browser compatibility issues between obscure browsers and the functions you're using
- Race conditions between elements loading on the page & your variant code running
- Trigger-happy test triggers
Even rock solid QA and deployment processes let bugs slip. You need to capture them when they happen in production:
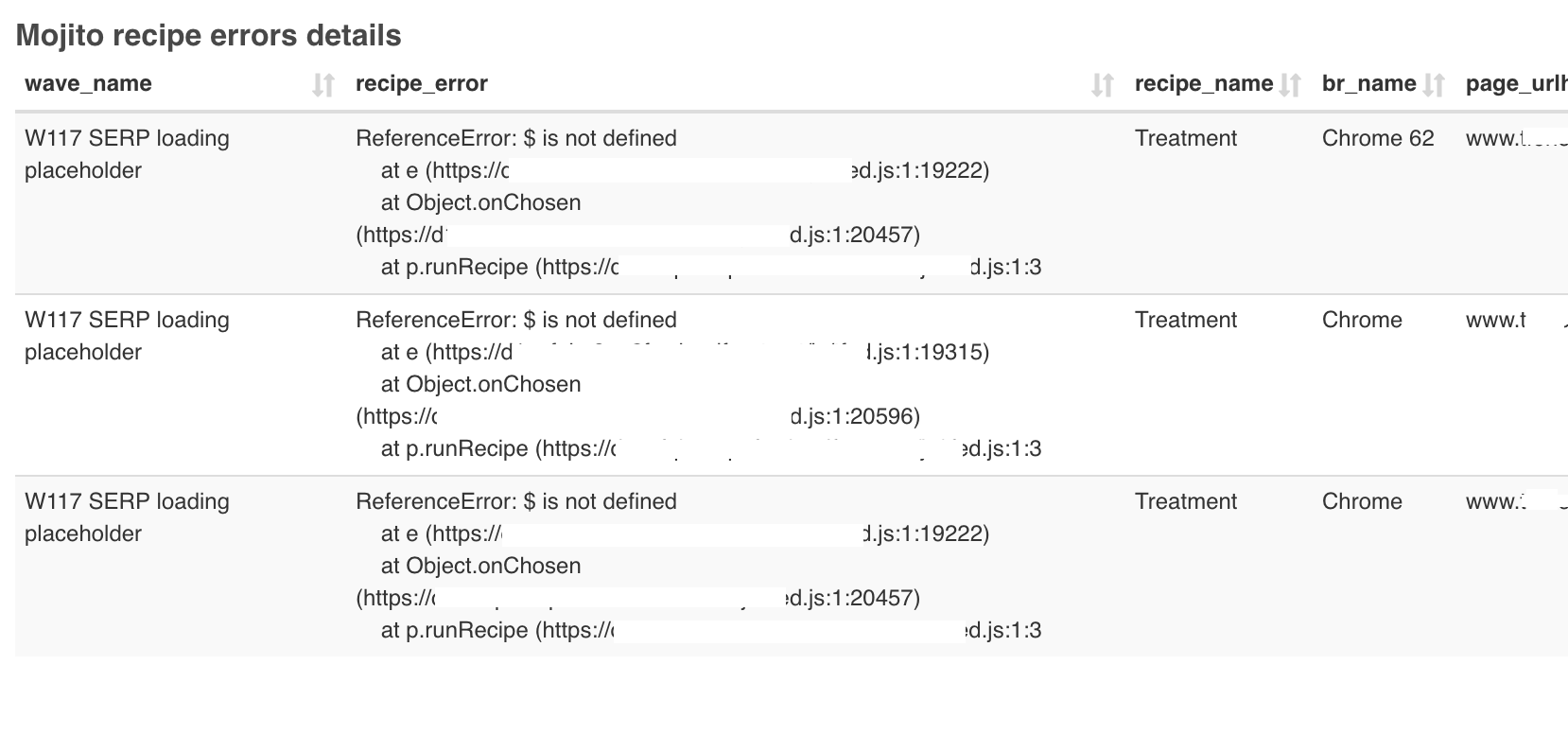
An example of typical race conditions being tracked inside Mint Metrics' Superset.
When errors occur, try to recover the user experience
Since most tests manipulate the DOM, a JS error half-way through the variant code can really break the page.
Imagine an experiment breaks a user's critical path to conversion... you're going to want to recover that experience smoothly and let the user continue to purchase. As long as you know an error has occurred, you can also take steps to handle it.
And often, recovery is as simple as excluding the user from the test and reloading the page:
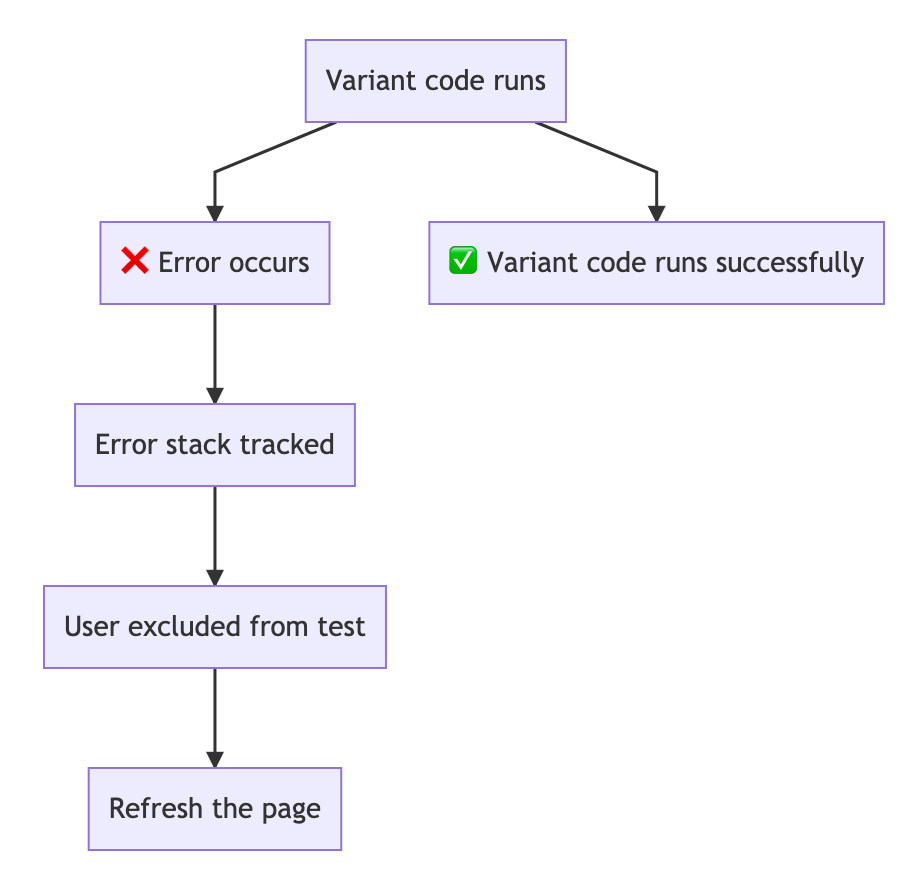
By excluding users from the test and refreshing the page, they'll see a small delay, but at least the page will work as expected when it reloads.
How to track & handle errors in JS
Just wrap the variant code in a try...catch statement. When errors pop up, you'll be able to take care of it. Boom. It's that easy.
try {
// Variant code
missingFunction();
} catch(error) {
// Track the error's stack trace
dataLayer.push({
'event': 'variant error',
'errorMessage': error.stack?error.stack:(error.message||error)
});
// Bump the user out of the test
// Refresh the page without the user in the experiment
setTimeout(function(){
// Wait 200ms so the tracking can fire reliably
window.location.reload();
}, 200);
}
Stepping through the logic, you can see how browsers will run the code:
- Try and run the variant code
- If any errors occur, push them into the catch function
- Track the error to your analytics tool
- Exclude the user from seeing the experiment
- Reload the page after 200ms
Note: It's important to wait for the tracking to run.
If you don't wait long enough, you risk reloading the page before the user was even tracked as part of the experiment - as I'll show later, this can result in a non-random selection bias. Basically, the control group will appear to have more users than the treatment group and throw off your results.
What to capture for error tracking
Our error tracking Snowplow events are simple and actionable - with just the right amount of information. We collect:
- Wave ID (Experiment ID)
- Wave name (Experiment name)
- Component (name of the treatment or trigger function the JS error is emanating from)
- Error (the error message and first 1000 characters of the stack message)
Here's our self-describing event's JSON schema:
{
"$schema" : "http://iglucentral.com/schemas/com.snowplowanalytics.self-desc/schema/jsonschema/1-0-0#",
"self" : {
"vendor" : "io.mintmetrics.mojito",
"name" : "mojito_failure",
"version" : "1-0-0",
"format" : "jsonschema"
},
"type" : "object",
"properties" : {
"waveId" : {
"type" : "string"
},
"waveName" : {
"type" : "string"
},
"component" : {
"type" : "string"
},
"error" : {
"type" : "string"
}
},
"additionalProperties" : false
}
And because we're Snowplow, we often link the information above to the page URLs and browser user agent. You could easily do the same with Google Analytics too!
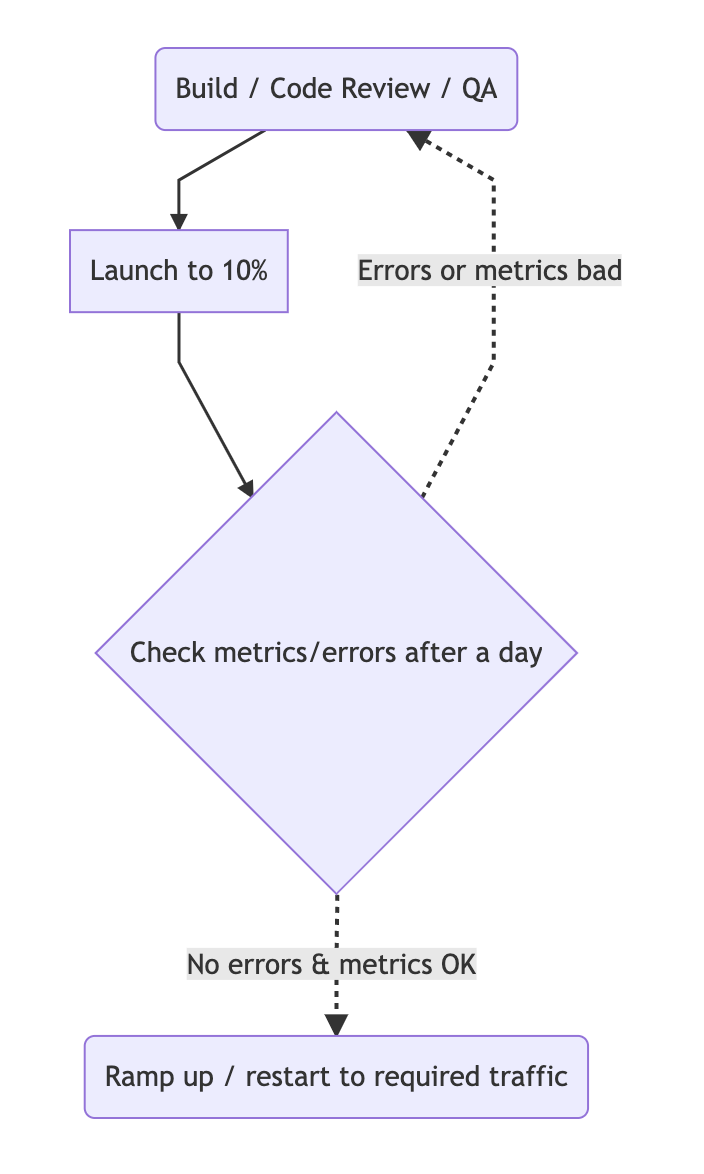
Practice gradual ramp-up to catch and fix errors early on
Just as you'd dip your toe in the water before jumping in the pool, you can dip only a few users into the experiment before it goes out to more traffic.
For critical experiments, you may decide to do a canary release to a fraction of traffic - like 10%. If everything looks healthy following a few hundred or thousand users, you can assign more traffic with confidence...
Here's how gradual ramp-up works with error tracking:
"Let's just exclude users with errors from analysis!" ... STOP!
Most errors are not randomly occurring. Before you introduce a form of non-random selection bias, consider how it affects your split test results.
Errors may be triggered by certain page views, events, by having a slow internet connection or by using a particular browser. Therefore, the conditions that land you in the "error prone" group of users also mark you as a very special type of user.
Think about Internet Explorer users, for example:
- They're very likely to throw JavaScript errors
- They're unlikely to convert
If you exclude this group of users from just the treatment group but not the control, you'll be removing lots of dud traffic from your treatment group, thus lifting it's conversion rate artificially!
Here's how it might play out:
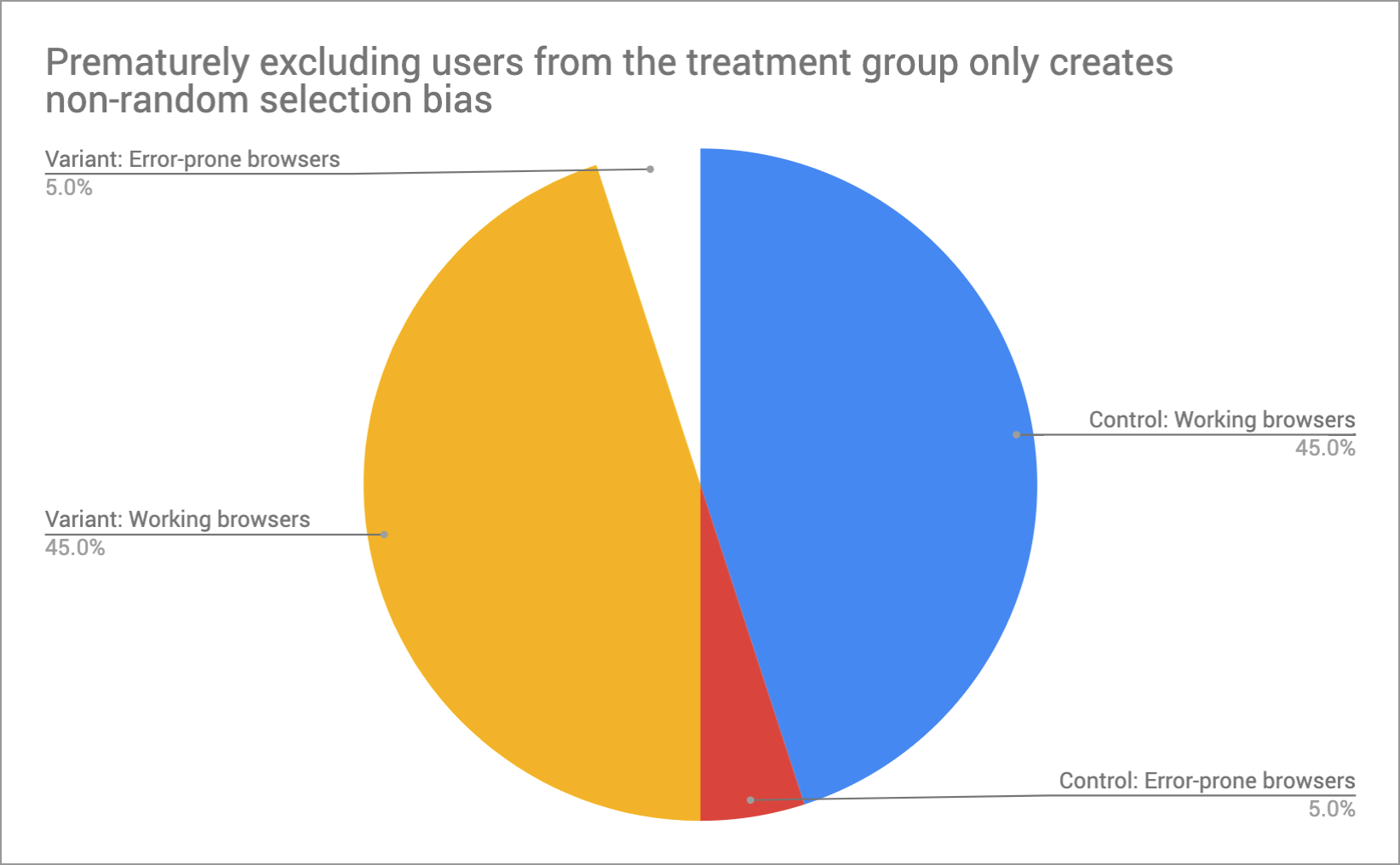
If you're going to retroactively exclude errors from your results, first identify the culprit browser on BOTH control and treatment groups... and then filter them out on both sides.
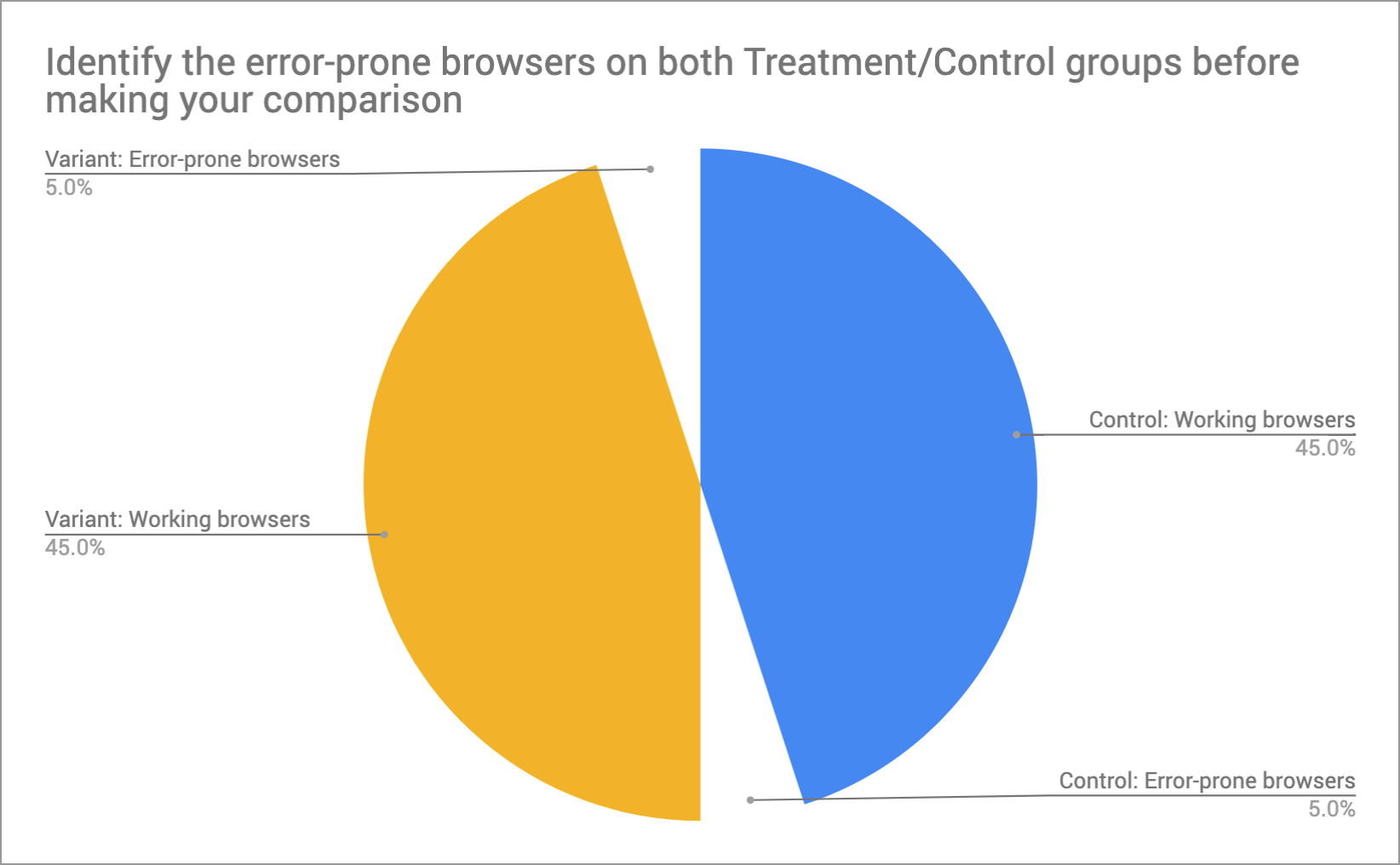
Often, older versions of IE are excluded from tests by default, so your results may already look like this without you knowing it!
Now you'll be comparing like-for-like groups. Thanks Johann de Boer, for sharing this nifty trick with us!
And better yet, you could fix and relaunch the experiment...
Fix & relaunch the experiment for the best results
By stopping and restarting with all users in the test, you'll know your experiment helps/hurts all traffic and not just a large segment.
Just make sure you remember to re-assign users after you fix the errors. You wouldn't want the errors occurring before the fix influencing your test results after it's squeaky clean.