Partitioned ramps: A surprising feature of using hash functions for A/B split tests

Whilst improving Mojito's PRNG & devising an ITP2.X workaround last year we introduced a modular splitting tool in Mojito that lets users split traffic with hash functions. We're amazed by the features that hash functions enable in split testing such as:
- Deterministic results: Users will always be bucketed the same way for a given input - regardless of when or where you're making the decision from (e.g. client-side/server-side/web/app)
- Sufficiently random: Random numbers are uniformly distributed despite near-identical inputs
But hiding in plain sight was a novel ramping process that Lukas Vermeer, Booking.com's Director of Experimentation, pointed out to us. We'd not encountered it before. But now that we were using hash functions, it was possible...
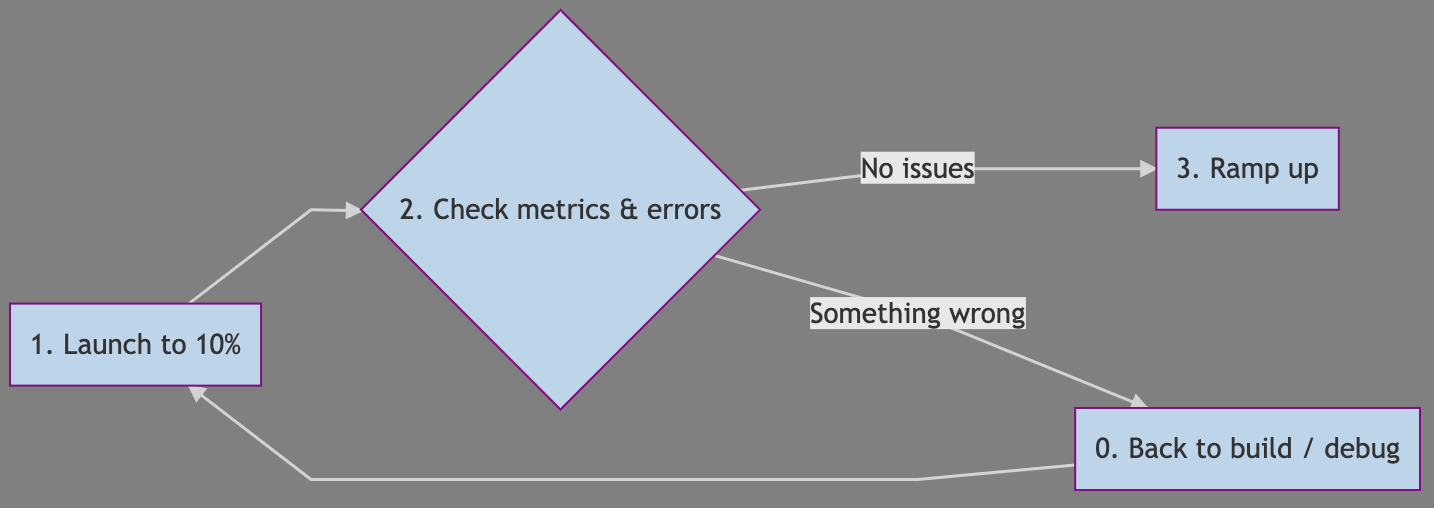
First, let's review problems with current ramping processes
Depending on your approach to ramping (e.g. 10% canary release, check metrics and "ramp-up" to 100%), you face some trade-offs:
Option 1: Straight ramp from canary
When you first launch to 10%, in your canary release, you'll exclude the other 90% of users from your experiment. These users will remain excluded for the rest of your experiment. And it can be an issue when large cohorts visit on particular days of the week (e.g. the Monday rush):
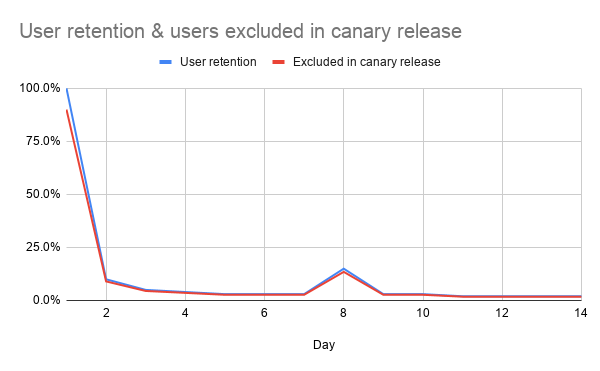
Loyal users may return frequently and it can resemble a chart like this. Despite returning after your initial ramp, they'll stay excluded from your test.
This tends to skew toward your most loyal, active users - those visiting daily or very frequently. And its effect can shroud the truth behind Simpson's paradox...
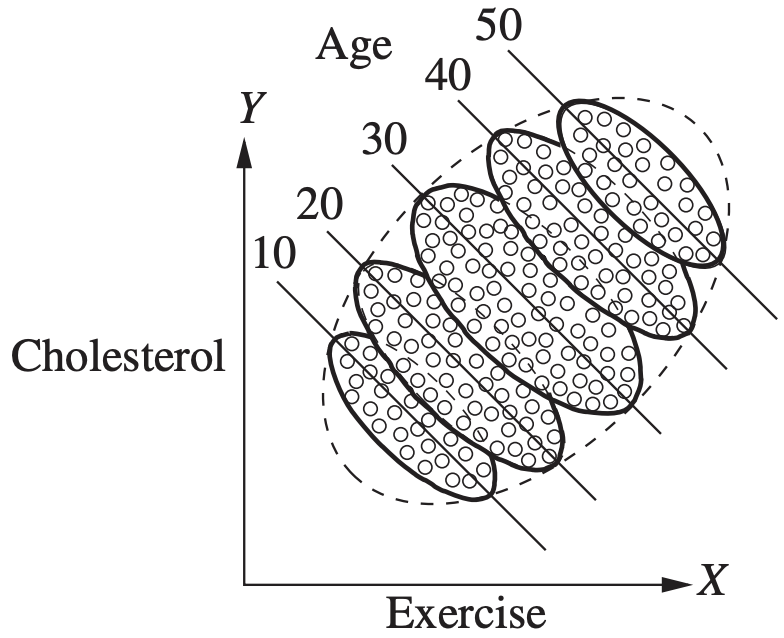
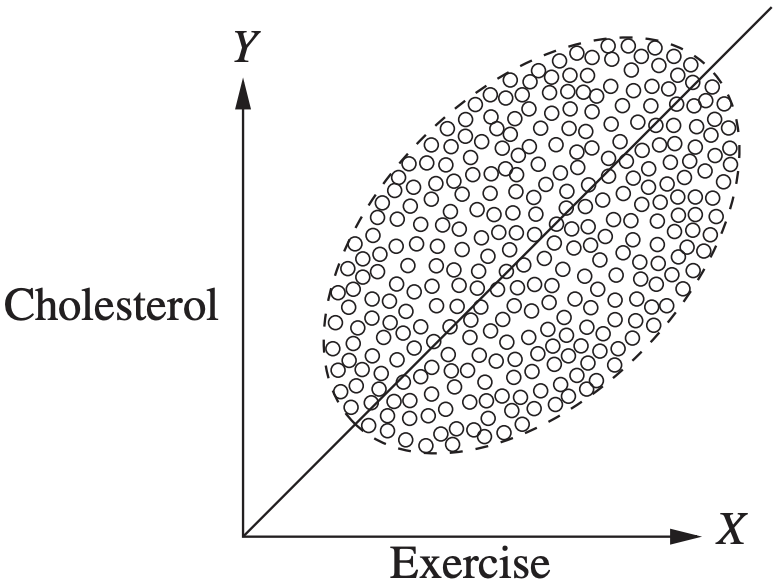
When aggregated, the data masks the true relationship between cause and effect. Source: J. Pearl, M. Glymour, and N.P. Jewell, Causal Inference in Statistics: A Primer, Wiley, 2016.
The only way to minimise Simpson's paradox using this method is choosing your start time wisely... and ramping up ASAP.
Option 2: Restart/Reassign & ramp-up
You can mostly avoid Simpson's paradox compared to the approach above if you stop, restart & reassign users. Those who were excluded in the canary release can be randomly reassigned back into your ramped experiment.
But users originally assigned to your treatment group have a 50-50 chance to be reassigned to your control group (and vice-versa). This can mute the effects of your treatment as users spillover between treatments.

Users from the canary release's population will be reassigned in your full ramp.
As with a straight ramp, users with an inconsistent experience often skew toward your most loyal users. If your split test reporting is sufficiently flexible, you can segment out these users from your results to mute this effect.

Introducing "Partitioned ramps"
Since hashes deterministically map User IDs to your buckets, you can easily contain the spillover across ramps:

Partitioned ramps keep your full ramp separate from your canary release.
It only costs a bit of statistical power (which you may be comfortable with):
- Partition 1: Canary release
- Include the first 10% of users
- Exclude the remaining 90%
- Partition 2: Full ramp
- Exclude the first 10% of users
- Include the remaining 90%
See a practical example implemented in Mojito
With Mojito's modular [decisionAdapter](https://mojito.mx/docs/js-delivery-api-decision-adapter), you can define your own bucketing logic or orchestrate even more sophisticated partitioned ramps. You only need a couple of parameters and our recommended decision adaptor to implement this:
state: live
id: ex3
name: Homepage button
recipes:
'0':
name: Control
'1':
name: Treatment
css: 1.css
trigger: trigger.js
Partitioned ramp parameters
Uncomment the options below depending on the partition you're ramping to.
1. Canary release parameters: 10% sample rate, disable cookies
#sampleRate: 0.1
#options:
# cookieDuration: -1
2. Ramp-up parameters: 100% sample rate, initial 10% excluded, cookies re-enabled (optional)
sampleRate: 1
excludeSampleRate: 0.1
See how to implement partitioned ramps it in Mojito.

Users in the "canary" release are only exposed during the "canary" period and they're not exposed during the "full ramp."
Credit to Lukas Vermeer
As noted at the start, credit to Lukas Vermeer for this great idea. We're grateful to him for sharing this creative, practical use case of hash-based split testing and ramping.
Your choice...
If you ramp experiments as part of your A/B testing process, you now have another approach to keep statistical gremlins out of your test results.