Why an A/B testing tool should form an experiments layer over your site

There's a reason tag managers are now the de facto for tag deployment.
Before tag managers, you'd embed tags directly into your application. It could take weeks or months to deploy them inside large, monolithic apps... Meanwhile, you'd be shifting precious developer time off high-value projects. And the practice of tagging the app just added further bloat/technical-debt to your heavy codebase.
...and then tag managers became popular.

Image credit: Blastam Analytics
Now, independent of the web application code, tags could be setup, QA'd and deployed before your coffee went cold. This led to an explosion in data collection and marketing efficiency.
This efficiency is critical in the fast-paced world of experimentation...
SaaS split testing vendors have been operating like "experiment tag managers" for a long time
Even before GTM and other tag managers were popularised, Sitespect, Optimizely and VWO were serving tests through, what I like to think of as, an experimentation layer.
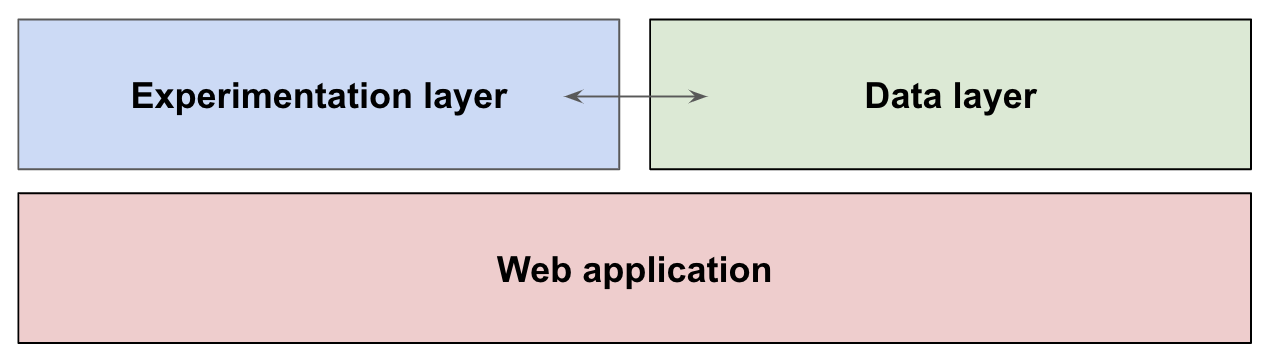
The result? Testing programs accelerated. While non-technical users built simple tests through WYSIWYGs, even developers' sped up their workflows as they built and published MVPs over the top of web apps. They could entirely bypass lengthy application deployments. In many ways, the SaaS vendors' "experimentation layer" workflow is almost identical to the data layer and the tag managers they feed.
Gone are the days your experiment needed:
- Lengthy application deployments
- More code and technical debt added to your application
- Developer time spent on building & launching simple, disposable tests
Sadly, open-source split testing tools missed this workflow opportunity
Of the few open-source experimentation tools around, Igor Ursiman (founder of another testing SaaS split testing tool provider), criticised them for having libraries and experimentation logic embedded inside monolithic web applications.
And he's right. You can't innovate quickly unless your experiment code is managed independently from your application codebase.
But we believe Mojito is a great experimentation layer
Mojito mimics the one-tag solution of many popular SaaS vendors, like Google Tag Manager, Optimizely and VWO. Our recommended implementation just needs a JS defined on the page:
<script type="text/javascript" src="//your.domain.name/mojito.js"></script>
The JS file stores everything, including:
- Split test library
- Tracking & config
- Experiment logic & variant code
Managing this JS file independently of your app means you'll practically never need to update your web application code for split testing your MVPs.
Use git to scale development across teams & developers
You also don't need to sacrifice control or scalability when you manage the Mojito container with git.
Another collaborative development project called Linux uses git to scale development on the Linux kernel. In just the last month, 600 developers added 1 million new lines of code and removed half a million lines!
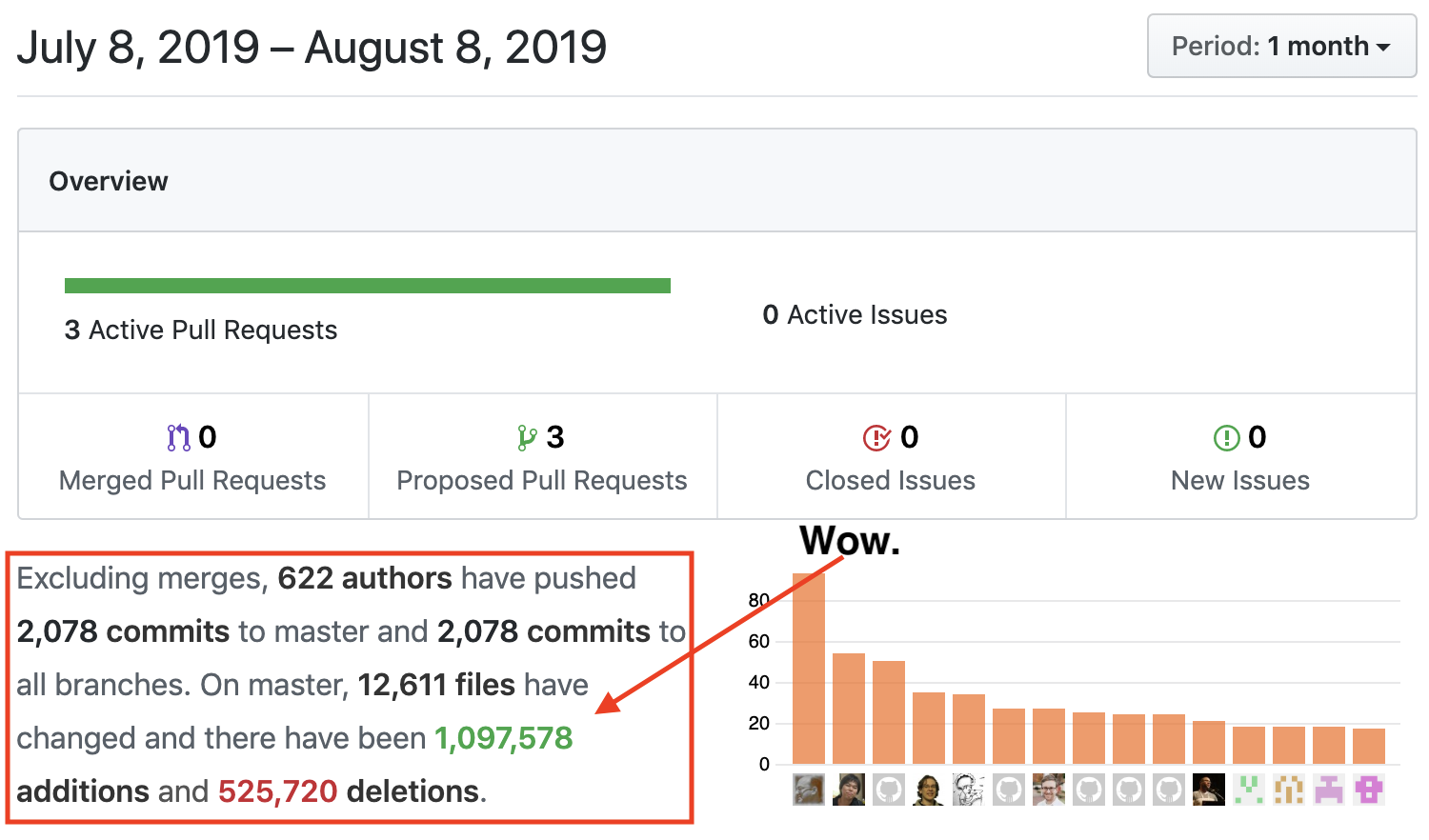
How do the maintainers manage so many commits and keep Linux stable? You've clearly got room to grow...
If all your developers are using git, they can easily hop into your Mojito project and start building and launching tests.
Plus, git facilitates code review & good deployment practices
Just because SaaS tools may hide buggy experiments and rough MVP-code doesn't mean you have to do the same with an open-source testing layer. Managing experiments in git, you can facilitate:
- Mandatory reviews as a merge check... tick!
- CI testing before publishing... tick!
- Stop copy/pasting into an external tool... tick!
- Remove surprises from your external JS container updating... tick!
- Fine-grained ACLs... tick!
Better experiment code keeps your application stable and gives your treatments the best shot at winning (or failing).
Tear-down data silos: Track experiment data into purpose-built analytics tools
We believe data from your experimentation layers need to tracked next to all the events an organisation collects. Purpose built tools like Adobe Analytics, GA or Snowplow Analytics are always going to beat black-box trackers used in SaaS tools.
Why bother adding and maintaining redundant, siloed trackers?

You don't need more data silos in your life. Image credit: Ixxus.
What do you think about the need for an experiments layer?
Let us know what you think in the comments!